此笔记是对 Redux 中文官网 中 state 范式化的总结。
1. State 范式化
事实上,大部分程序处理的数据都是嵌套或互相关联的。例如,一个博客中有多篇文章,每篇文章有多条评论,所有的文章和评论又都是由用户产生的。这种类型应用的数据看上去可能是这样的:
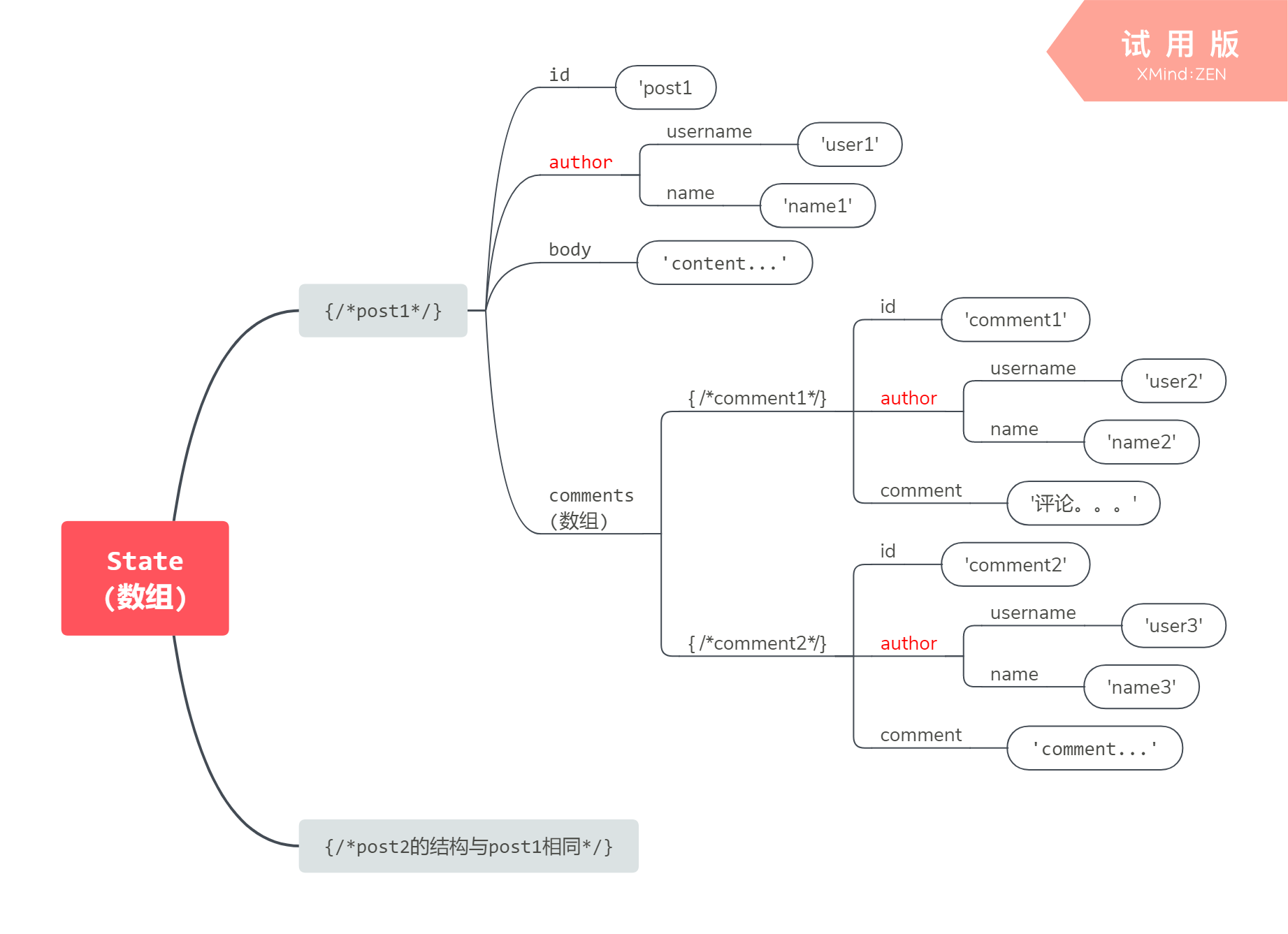
这种结构的特点是很直观,跟页面结构一致,但存在以下几个问题:
- 1) 当数据在多处冗余后,需要更新时,很难保证所有的数据都进行更新。
- 2) 嵌套的数据意味着 reducer 逻辑嵌套更多、复杂度更高。尤其是在打算更新深层嵌套数据时。
- 3) 可变的数据在更新时需要状态树的祖先数据进行复制和更新,并且新的对象引用会导致与之 connect 的所有 UI 组件都重复 render。尽管要显示的数据没有发生任何改变,对深层嵌套的数据对象进行更新也会强制完全无关的 UI 组件重复 render。
关于第1个问题,比如上图中的用户: author ,用户既可以是文章的作者,又可以在自己文章或别人文章后留言。如果现在需要修改其 name 的值,我们得在多处进行更新,这是十分困难的。
范式化的数据包含下面几个概念:
- 1) 任何类型的数据在 state 中都有自己的 “表”。
- 2) 任何 “数据表” 应将各个项目存储在对象中,其中每个项目的 ID 作为 key,项目本身作为 value。
- 3) 任何对单个项目的引用都应该根据存储项目的 ID 来完成。
- 4) ID 数组应该用于排序。
上面博客示例中的 state 结构范式化之后可能如下:
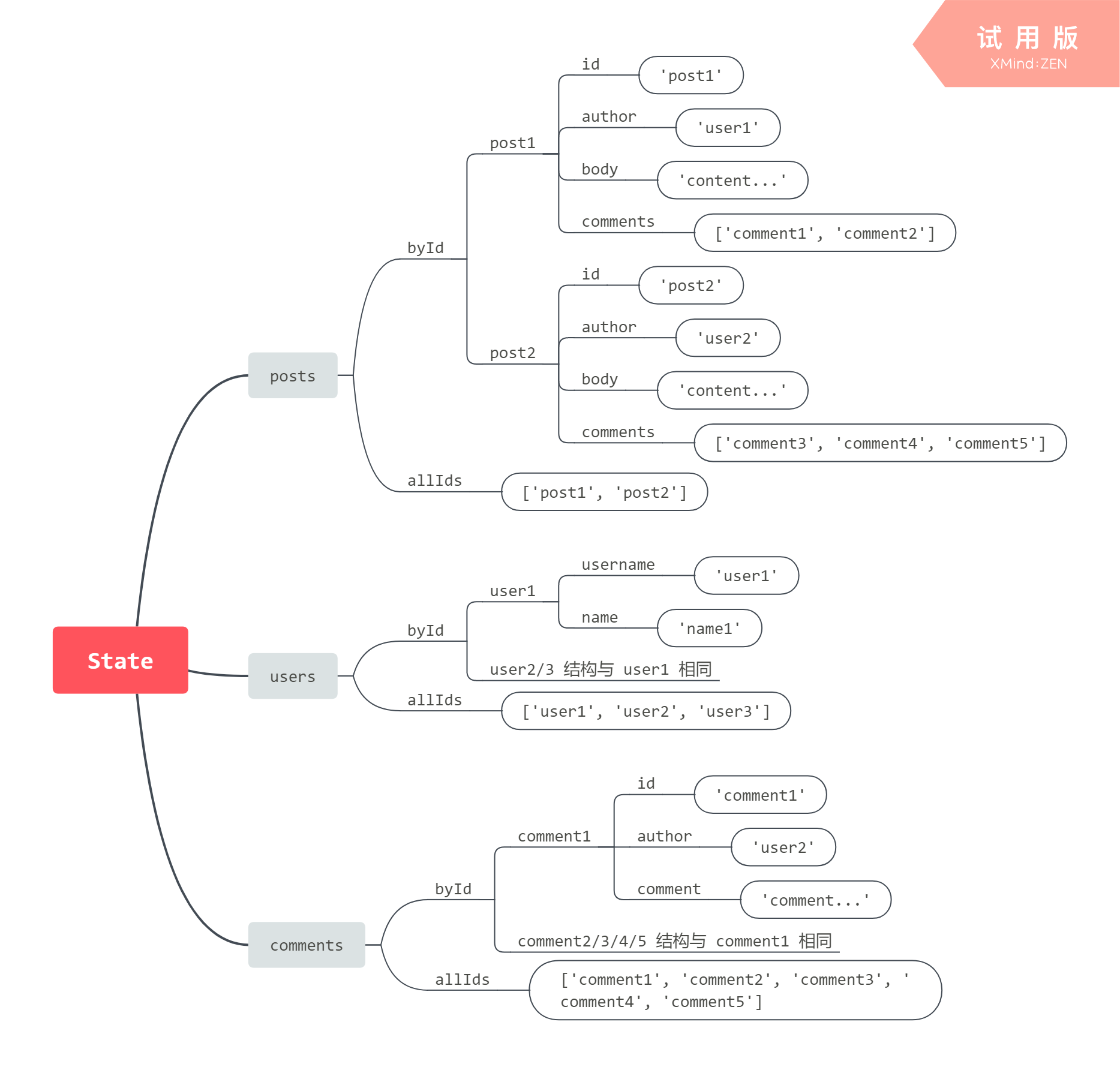
这种 state 在结构上更加扁平。与原始的嵌套形式相比,有下面几个地方的改进:
- 1) 每个数据项只在一个地方定义,如果数据项需要更新的话不用在多处改变。
- 2) reducer 逻辑不用处理深层次的嵌套,因此看上去可能会更加简单。
- 3) 检索或者更新给定数据项的逻辑变得简单与一致。给定一个数据项的 type 和 ID,不必挖掘其他对象而是通过几个简单的步骤就能查找到它。
- 4) 每个数据类型都是唯一的,像改评论这样的更新仅仅需要状态树中 “comments > byId > comment” 这部分的复制。这也就意味着在 UI 中只有数据发生变化的一部分才会发生更新。
与之前的不同的是,之前嵌套形式的结构需要更新整个 comment 对象,post 对象的父级,以及整个 post 对象的数组。这样就会让所有的 Post 组件和 Comment 组件都再次渲染。
需要注意的是,范式化的 state 意味更多的组件被 connect,每个组件负责查找自己的数据,这和小部分的组件被 connect,然后查找大部分的数据再进行向下传递数据是恰恰相反的。事实证明,connect 父组件只需要将数据项的 Id 传递给 connect 的子对象是在 Redux 应用中优化 UI 性能的良好模式,因此保持范式化的 state 在提高性能方面起着关键作用。
2. 管理范式化 State
如果我们有一个由切片 reducer 组成的嵌套数据,每个切片 reducer 都需要知道如何响应这个 action。因为我们需要让 action 囊括所有相关的数据。
比如我们需要给某一篇文章新增一条评论,action 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// actions.js
function addComment(postId, commentText) {
// 为这个 comment 生成一个独一无二的 ID
const commentId = generateId('comment')
return {
type: 'ADD_COMMENT',
payload: {
postId,
commentId,
commentText
}
}
}
在 dispatch 此 action 之后,Reducer 应该完成如下几个地方的数据更新:
- 1)
state => posts => byId => postId => comments(修改指定文章所有评论的 id 数组) - 2)
state => comments => byId => commentId(新增一个 comment 对象) - 3)
state => comments => allIds(修改所有评论的 id 数组)
Reducer 的设计如下:
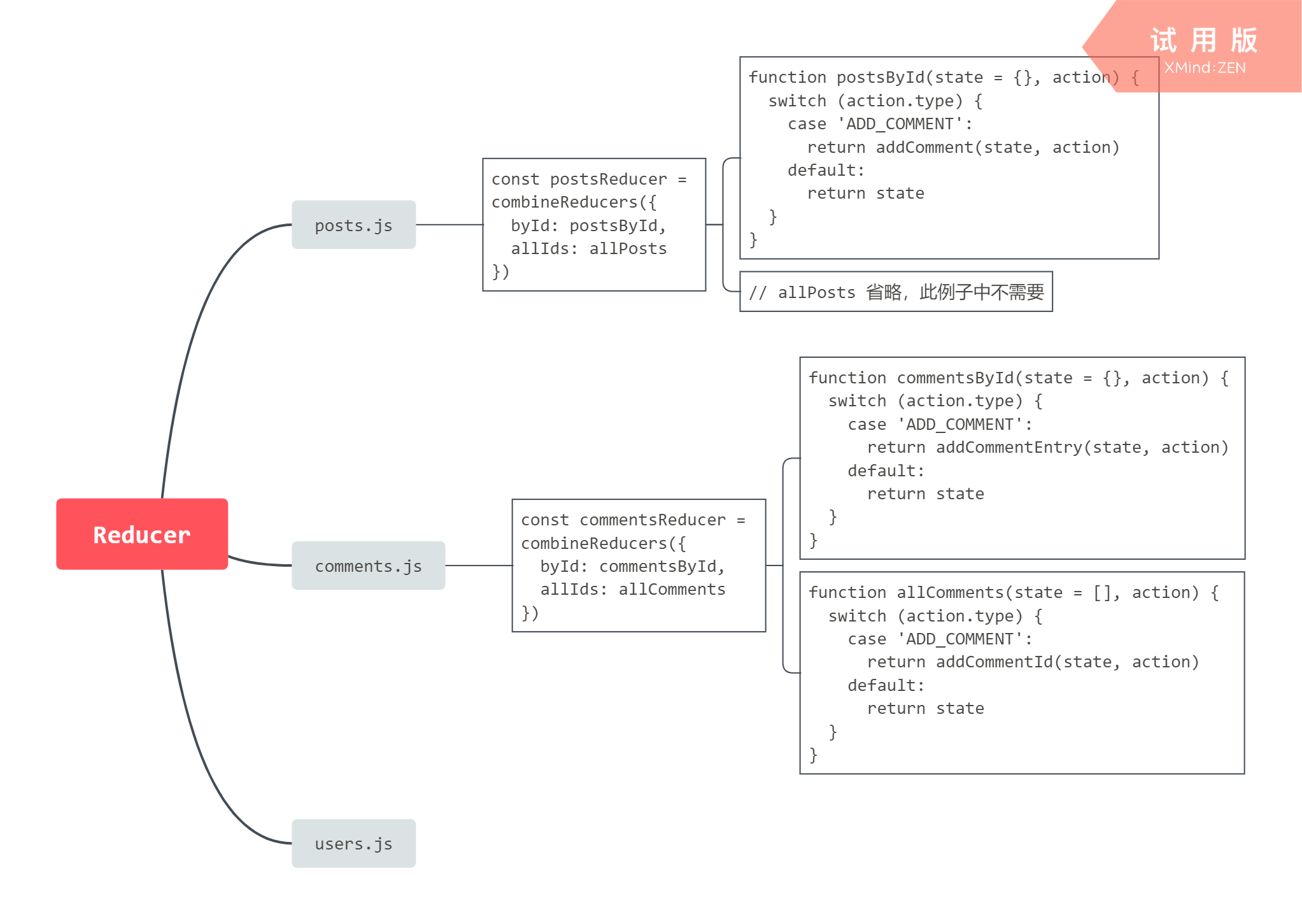
其中 posts.js 中的 addComment 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function addComment(state, action) {
const { payload } = action
const { postId, commentId } = payload
// 查找出相应的文章,简化其余代码
const post = state[postId]
return {
...state,
// 用新的 comments 数据更新 Post 对象
[postId]: {
...post,
comments: post.comments.concat(commentId)
}
}
}
comments.js 中的 addCommentEntry 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
function addCommentEntry(state, action) {
const { payload } = action
const { commentId, commentText } = payload
// 创建一个新的 Comment 对象
const comment = { id: commentId, text: commentText }
// 在查询表中插入新的 Comment 对象
return {
...state,
[commentId]: comment
}
}
comments.js 中的 addCommentId 如下:
1
2
3
4
5
6
function addCommentId(state, action) {
const { payload } = action
const { commentId } = payload
// 把新 Comment 的 ID 添加在 all IDs 的列表后面
return state.concat(commentId)
}
这个例子之所有有点长,是因为它展示了不同切片 reducer 和 case reducer 是如何配合在一起使用的。注意这里对 “委托” 的理解。postById reducer 切片将工作委拖给 addComment,addComment 将新的评论 id 插入到相应的数据项中。同时 commentsById 和 allComments 的 reducer 切片都有自己的 case reducer,他们更新评论查找表和所有评论 id 列表的表。